AG真人(中国)官方IOS|Android手机app下载 英伟达: 带领 PC, 重铸 PC|硬形而上学


爱范儿情愫「明日产物」,硬形而上学栏目试图剥离本领和参数的外套,探求产物设计中东谈主性的本源。
曩昔 48 小时,关于 Windows 电脑商场来说可谓地震束缚——
不是微软要发 Win 12 了,也不是苹果再行内置 BootCamp 了,而是英伟达要造消费级 CPU了。

图|Microsoft
更蹙迫的是,老黄参加 CPU(SoC)范畴,可不是来和英特尔、AMD 和苹果分蛋糕的……
他是来掀桌子的。

图|YouTube @Nvidia
在刚终端的微软 Build 与英伟达 GTC 显卡本领大会开幕式上,咱们见到了来自英伟达的「终极 PC 处治决议」: RTX Spark N1X 处理器。
老黄盼望通过 RTX Spark 打造的电脑很苟简:
造出现在最全能、最智能、最面向改日十年以至二十年 AI 潮水的终极 Windows 全能本。
守旧英伟达这一设计的根底逻辑,是老黄在 GTC 开幕演讲上的一个斗胆判断——
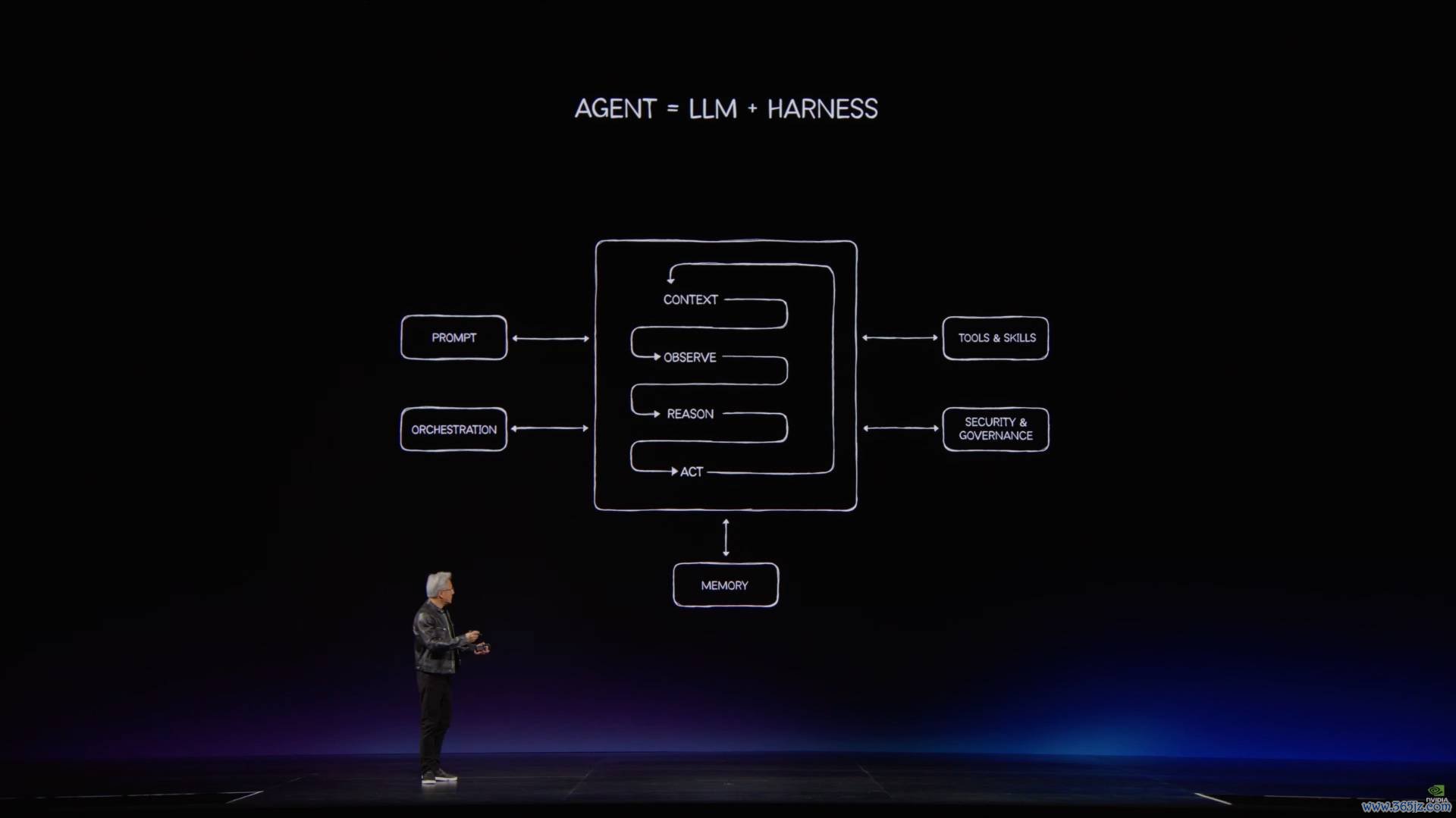
面向东谈主类用户设计计较产物的期间仍是终端,改日咱们应该面向智能体(intelligent agent)的需求设计计较硬件。
图|YouTube @Nvidia
下一个 AI 期间属于智能体
开场不久,先容过 AI 本领如何塑造了当下的产业经济之后,老黄就拿出了他本次演讲的中枢不雅点:
比拟单独使用某个 LLM(诳言语模子),智能体将是下一个阶段咱们使用算力的主要神气(a new kind of computing pattern)。
这个中枢不雅点如斯蹙迫,以至于老黄在演讲的前中后期反反复复拿起这一页 keynote,将它疏导播放了好多遍。
通盘演讲上公布的新硬件——比如认真投产的 Vera Rubin 计较平台、企业级 AI 器用包、底层模子等等,十足是围绕着这个中枢引子而设计的。

图|YouTube @Nvidia
把柄老黄的先容,智能体之是以概况成为下一阶段的核默算力使用神气,原因主要有 4 个——
1:目田用户坐褥力
曩昔几年里,单纯的生成式 AI(Generative AI)诚然才气得到了很大的普及,但并莫得拓展出相配多的使用场景。
即使它不错绘制、作念视频、凯旋制作各式文献,但骨子交互神气依然是用户问一句、AI 答一句。
智能体则否则——它的运作模式中包含「不雅察、推理、筹办、使用器用」的闭环才气,这种模式让东谈主类用户从器用操作家进化成了器用率领者,不错被看作是一种情势的坐褥力目田。
2:减少隐性资源浮滥
2026世界杯中国最新押注app除了自身的运行模式以外,智能体还会透顶改变曩昔半个多世纪中,东谈主类与计较机的中枢东谈主机交互模式。
换言之,智能体将也曾需要手动通达圭臬、点击器用和操作的经过后置了一步,让东谈主的责任从「来源」酿成了「动口」,用阐扬意图(intents)取代具体的操作。
这种变化的意念念,在于它终端了「东谈主学习和安妥软件」的期间。而一个「软件学习和安妥东谈主」的阶段,将会勤俭多半东谈主类学习和郑重使用软件所需的时期资源。
3:无视物理数目放弃
最「鼎力出遗址」的优点是,智能体不会像东谈主类一样,受到各式原因导致的数目放弃。
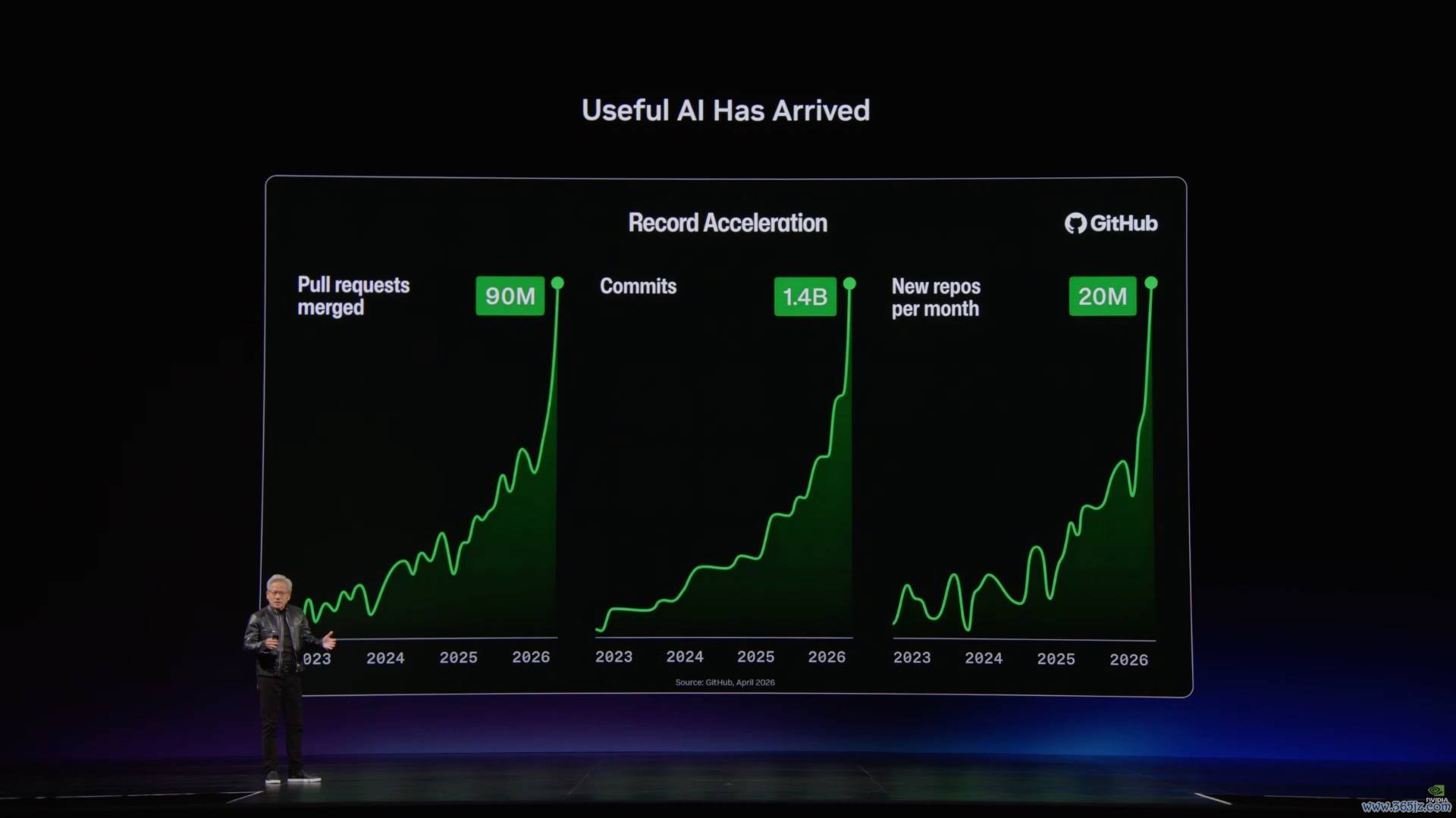
在演讲中,老黄列举了几个例子:AI 编码智能体的出现,让 GitHub 上的代码提交量在 2026 年头同比近乎翻了三倍。
英伟达里面也筹画通过部署「数十万个 Cadance 超等智能体」,将芯片设计考证的耗时从数周斥责到数小时。
换言之:只好算力资源允许,智能体就不错将单个东谈主类的才气「超等加倍」,让坐褥力获取指数级放大。
4:比 LLM 更全能
比拟传统 LLM,智能体还领有一个相配具体的上风——普适性。
智能体的运作模式(模子 + 外壳 + 器用 + 运行环境)在通盘掌握场景中齐是通配的,这种坚决的通用性让它不错落井下石。
比如大范畴的云表 SaaS 就业、个东谈主电脑部署、自动驾驶和东谈主形机器东谈主底层系统等等。
也即是说,智能体是 LLM 的一个「全能接口」,它我方即是齐备的器用组件、不错凯旋镶嵌具体的坐褥情势里,不需要东谈主类在中间虚浮地作念「回复搬运工」。
图|YouTube @Nvidia
基于以上四点论据,老黄指出了一种「面向智能体」的算力设计念念路:
曩昔四十多年,通盘计较硬件齐是围绕东谈主类的需求设计的,但智能体的天下以纳秒计较、关于各式资源(比如内存和电力)的需求模式和东谈主类天渊之别。
在这么的大配景下,老黄通知了新一代全栈 POD 超等计较平台「Vera Rubin」的认真投产:

图|YouTube @Nvidia
比拟年头在 CES 上初次先容 Vera Rubin 平台,老黄在演讲中再次强调了这一代架构「专诚为智能体设计」的属性。
尤其最新的 Vera CPU,就凯旋打上了「CPU for Agents」的标签——这颗 88 中枢 176 线程的处理器的主要责任,用老黄的话说,是一位「率领家」。
换言之,Vera CPU 主要适度智能体的调动、器用调用、内存和险峻文管制,负责将 Rubin GPU 的巨量算力以最高效果、最低空置、最快速率的神气调动起来:

图|YouTube @Nvidia
在此基础上,其他机柜组件—— BlueField-4 DPU、NVL72 交换机、ConnectX-9 SuperNIC 网卡、Spectrum-6 以太网交换机等等,才能和 Vera Rubin 共同组成这套「面向智能体」的算力处治决议。

图|YouTube @Nvidia
但就像前边说的,老黄除了公布 Vera Rubin 投产以外,同期也将这个「AI 的改日属于智能体」的不雅点投向了一个更偏向消费电子的范畴—— PC。
给智能体设计的电脑
之前提到,老黄本年 GTC 开幕演讲的主旨其实就一句话:
给东谈主类用户设计硬件的期间终端了,AG真人咱们下一步要面向智能体设计硬件。
但智能体的使用者不啻 Oracle、OpenAI、Anthropic、AWS 这些企业巨头,个东谈主 AI 用户的数目通常不可冷漠。
为了占住极为散播但范畴弘远的 C 端商场,老黄在本年的演讲中公布了英伟达首款面向个东谈主消费商场的 CPU 产物—— RTX Spark 超等芯片。

图|YouTube @Nvidia
老黄对 RTX Spark 首型号 N1X 的先容十分动情:「它汇集了咱们 33 年来的沿途本领教学,因为它支抓通盘英伟达已有的本领栈」。
与苹果的 Apple Silicon 念念路肖似,RTX Spark N1X 是一块集成 CPU、GPU 和调和内存的 ARM 架构 SoC,选定台积电 3nm 工艺制造,CPU 与联发科共同设计。

图|Nvidia
尽管用着上一代 Grace Blackwell 平台,而非最新的 Vera Rubin,RTX Spark N1X 依然不错罢了最高 1 PFLOPS(一千万亿次浮点)的 AI 算力。
把柄英伟达工程师的先容,N1X 的举座性能与 RTX 5070 条记本接近,比拟早期裸露的「与 M3 Max 跑分近似」又有了一些普及:

图|YouTube @Nvidia
在产物形态方面,RTX Spark 最主要的平台将会是 14-16 寸的条记本,互助方亦然那几个熟悉的巨头——理想、微软、惠普、华硕等等。
其中当属英伟达与微软的互助最为密切,毕竟 RTX Spark 是要运行 Windows on ARM 的。
而老黄的 ARM 处理器能否追上苹果,微软是其中不可或缺的要素。
相应的,微软也在演讲后更新了搭载 RTX Spark 的 Surface Laptop Ultra 预报片:

图|YouTube @Microsoft Surface
而比拟高通的 ARM 架构条记本,RTX Spark 还有一个先天不足的上风:它支抓通盘英伟达仍是有的本领,从清朗跟踪到 DLSS,再到 Cuda 加快和 TensorRT。
换言之,RTX Spark 条记本不仅有 Win on ARM 上相对优秀的游戏体验,更是概况在土产货 AI 器用加快之类的严肃场面提供「真材实料的坐褥力」。
图|YouTube @Nvidia
更蹙迫的是——按照老黄的说法—— RTX Spark 所驱动的条记本、袖珍主机和台式机齐是「为智能体操作而设计」的。
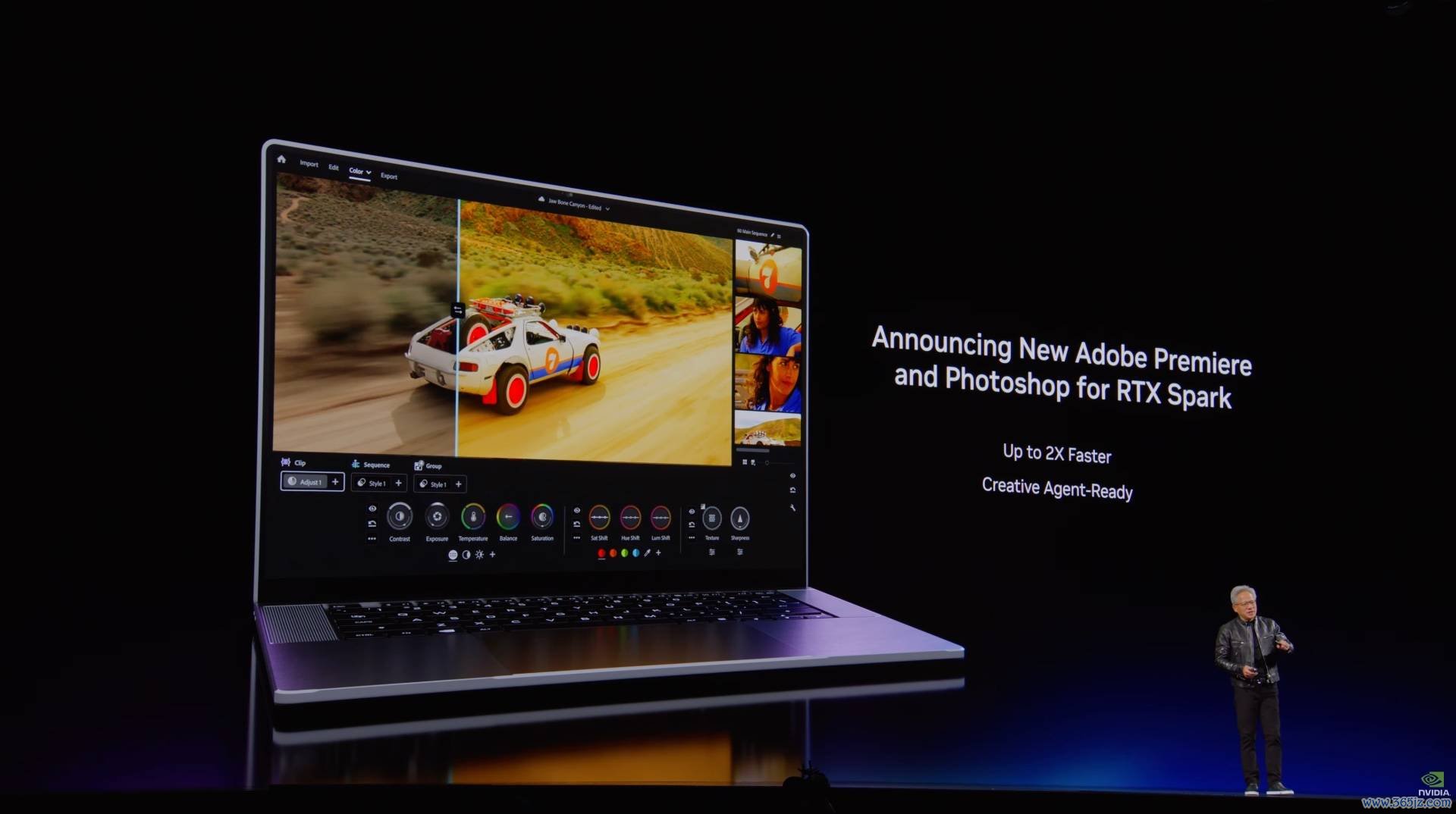
除了 Windows 自己和软件商以外,以至连 Adobe 齐通知将会为 RTX Spark 透顶重构 Premiere 和 Photoshop:
图|YouTube @Nvidia
就拿 Premiere 来说,Adobe 将会在 RTX Spark 电脑上带来一套全新的、以率领智能体为主的交互模式,以及更多的MCP 支抓。
再斗胆少量设计,通盘裁剪师齐熟悉的「时期轴式 UI」很有可能在智能体期间被一个多模态领导框所替代——
听起来很酷,也很可怕。

在 RTX Spark 笔电上运行 Premiere Pro|Tom’s Guide
换言之,AI 不仅重塑了硬件的设计神气,也终于开动重塑一些已成定局十多年的软件 UI 交互圭表了。
RTX Spark 的掌握场景也不啻笔电,在老黄的 GTC 开幕演讲与今日稍晚些的微软开发者 Build 大会上,咱们看到了好多以此为基础的袖珍主机平台。
就比如这个长得酷似 Xbox 的微软 RTX Spark Dev Box:

图|Microsoft
AI 需求塑造物理天下
纵不雅老黄的通盘 GTC 演讲,以及同期召开的 COMPUTEX 和微软 Build 大会,咱们不错彰着地感受到:
AI 从「生成式」向「智能体」的改动,将会重塑东谈主们使用计较机的主要神气,况兼这种重塑也反过来影响了计较硬件险峻游的设计和形态。
换言之,英伟达不仅界说了下一个 AI 期间的中枢问题:「什么是坐褥力 – 是智能体」,更是为我方的不雅点拿出了一套十分具有劝服力的配套产物。

图|YouTube @Nvidia
而 RTX Spark 的蓄意,是让新期间的全能本既要土产货跑模子,又要兼顾坐褥力和文娱——
毕竟支抓 RTX 和 Cuda 关于 Windows on ARM 一直是个老浩劫问题,直到英伟达躬行下场。
只不外在为下一个 AI 期间催生新硬件感到欢叫的同期,咱们也需要感性地看待 RTX Spark N1X 处理器:因为它并不是一个相配崭新的东西。

还牢记客岁的 DGX Spark 吗?里面的「GB10 超等芯片」基本上即是 N1X 的先行版块。
从芯移时字上看,老黄在 COMPUTEX 上展示的 N1X 坐褥周期以至是 2024 年,早期裸露跑分接近 2023 年的 M3 Max 也就不虞外了。

图|YouTube @High Yield
诚然通盘消费级产物齐要比及本年秋天,但看到 RTX Spark N1X 的这些稀薄信息,也很难不让东谈主微微悲哀——
一颗 CPU 两年前、GPU 一年前且起火血的 SoC,真能为改日 10 年 20 年的智能体需求准备好吗?
尽管 N1X 既没用上最新的 Vera Rubin 架构,也不如本年的骁龙 X2 Elite Extreme 以至客岁的 AMD Strix HALO,但它秀丽着一个最先:
一个芯片优先商酌智能体需求、并趁势开动影响操作系统、软件圭臬,直至硬件商品形态的期间的最先。
至于究竟谁能代表 AI 期间的操作系统,微软聘用和英伟达联手,「再给 Win on ARM 一个契机」,彰着是意志到了我方被 macOS 和 Linux 夹击的窘境。
图|Microsoft
然则成也 Win on ARM,败也 Win on ARM —— RTX Spark 主动带来全套的英伟达本领适配,并弗成处治 Win on ARM 在其他体验上的长久瘸腿。
毕竟一个迷漫好的面向 AI 的操作系统(比如 macOS),即使它我方不倾向于开放,也会有效户通过逆向工程的神气帮它开放。
而在这一层上,RTX Spark + Win on ARM 是以存身的基点AG真人(中国)官方IOS|Android手机app下载,就显得不是那么相识了。